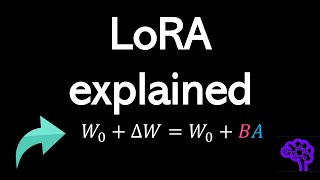Published On Mar 28, 2023
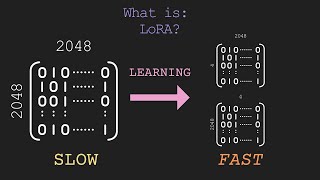
Your GPU has not enough memory to fine-tune your LLM or AI system? Use HuggingFace PEFT: There is a mathematical solution to approximate your complex weight tensors in each layer of your self-attention transformer architecture with an eigenvector and eigenvalue decomposition, that allows for a minimum memory requirement on your GPU / TPU.
The HuggingFace PEFT library stands for parameter-efficient fine-tuning of transformer models (LLM for language, Stable Diffusion for images, Vision Transformer for vision) for reduced memory size. And one method of PEFT is LoRA: Low-rank Adaptation of LLMs.
Combined with setting the pre-trained weights to non-trainable and maybe even consider a 8bit quantization of your pre-trained LLM model parameters, a reduced memory footprint of adapter-tuned transformer based LLM models achieves SOTA benchmarks, compared to classical fine-tuning of Large Language Models (like GPT, BLOOM, LLama or T5).
In this video I explain the method in detail: AdapterHub and HuggingFace's new PEFT library focus on parameter-efficient fine-tuning of transformer models (LLM for language, Stable Diffusion for images, Vision Transformer for vision) for reduced memory size.
One method, Low-rank Adaptation, I explain in detail for an optimized LoraConfig file when adapter-tuning INT8 quantization models, from LLMs to Whisper.
Follow up video: 4-bit quantization QLoRA explained and with colab Notebook:
• Understanding 4bit Quantization: QLoR...
#ai
#PEFT
#finetuning
#finetune
#naturallanguageprocessing
#datascience
#science
#technology
#machinelearning